heaplens
instant jvm heap dump analysis, right in your browser
a fast, web-based HPROF heap dump analyzer that starts showing results the moment you upload a file. class histograms appear in under a second, the full dominator tree builds in the background, and the entire experience runs from a single static binary with zero external dependencies.
built with rust to explore streaming heap dump analysis and performance tooling. no jvm, no database, no config files.
key features
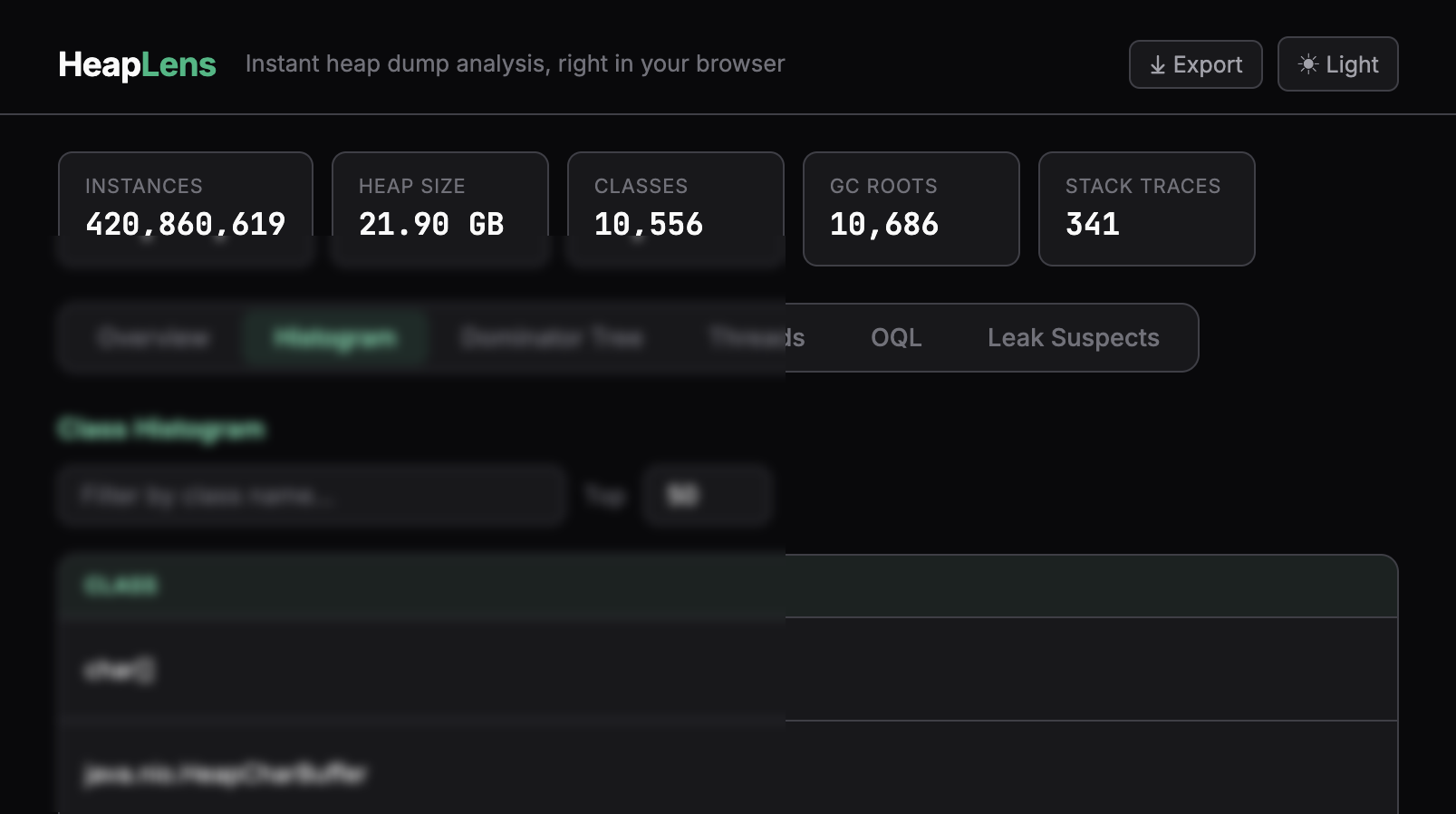
- streaming results — histogram updates live as bytes arrive
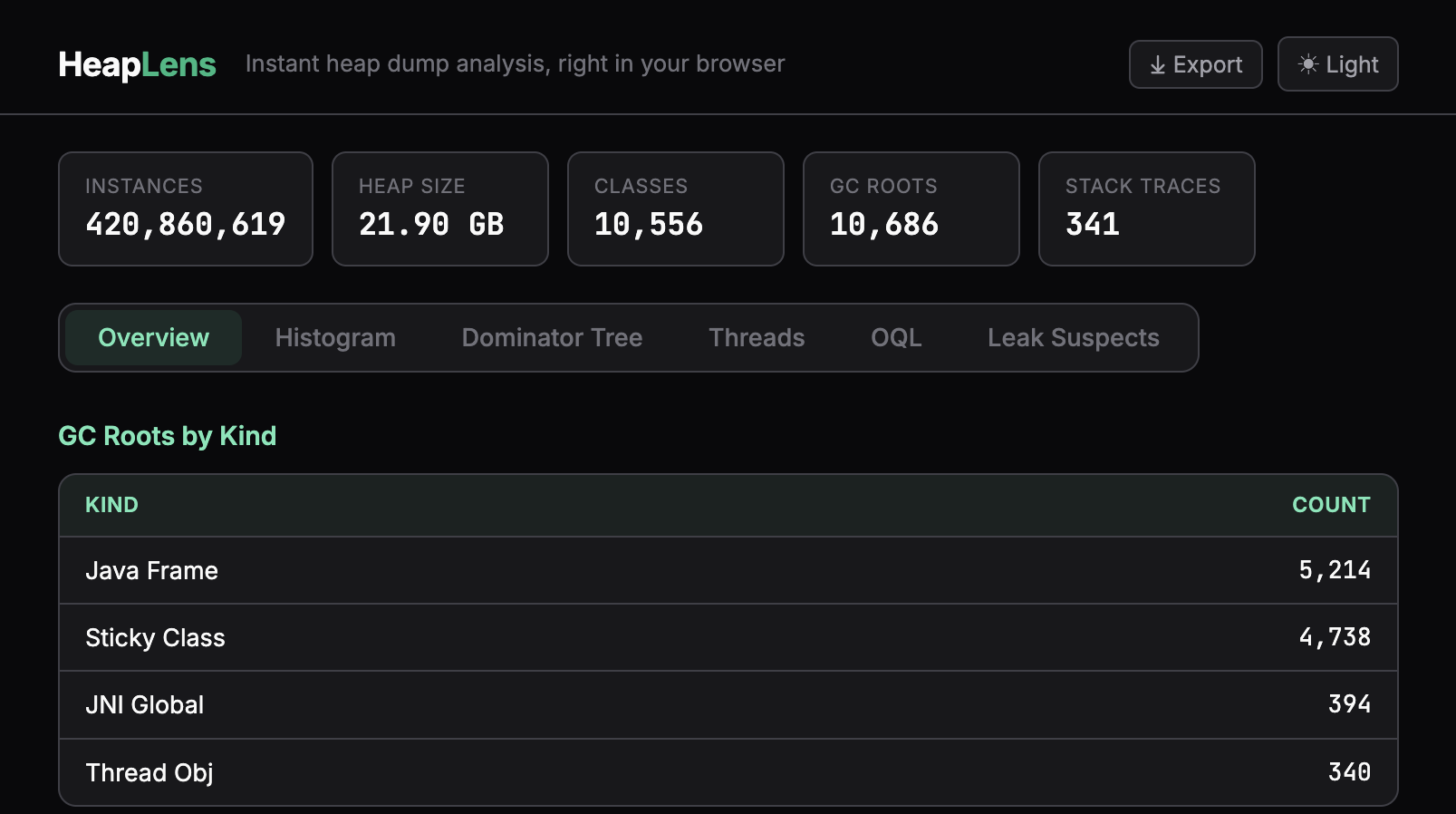
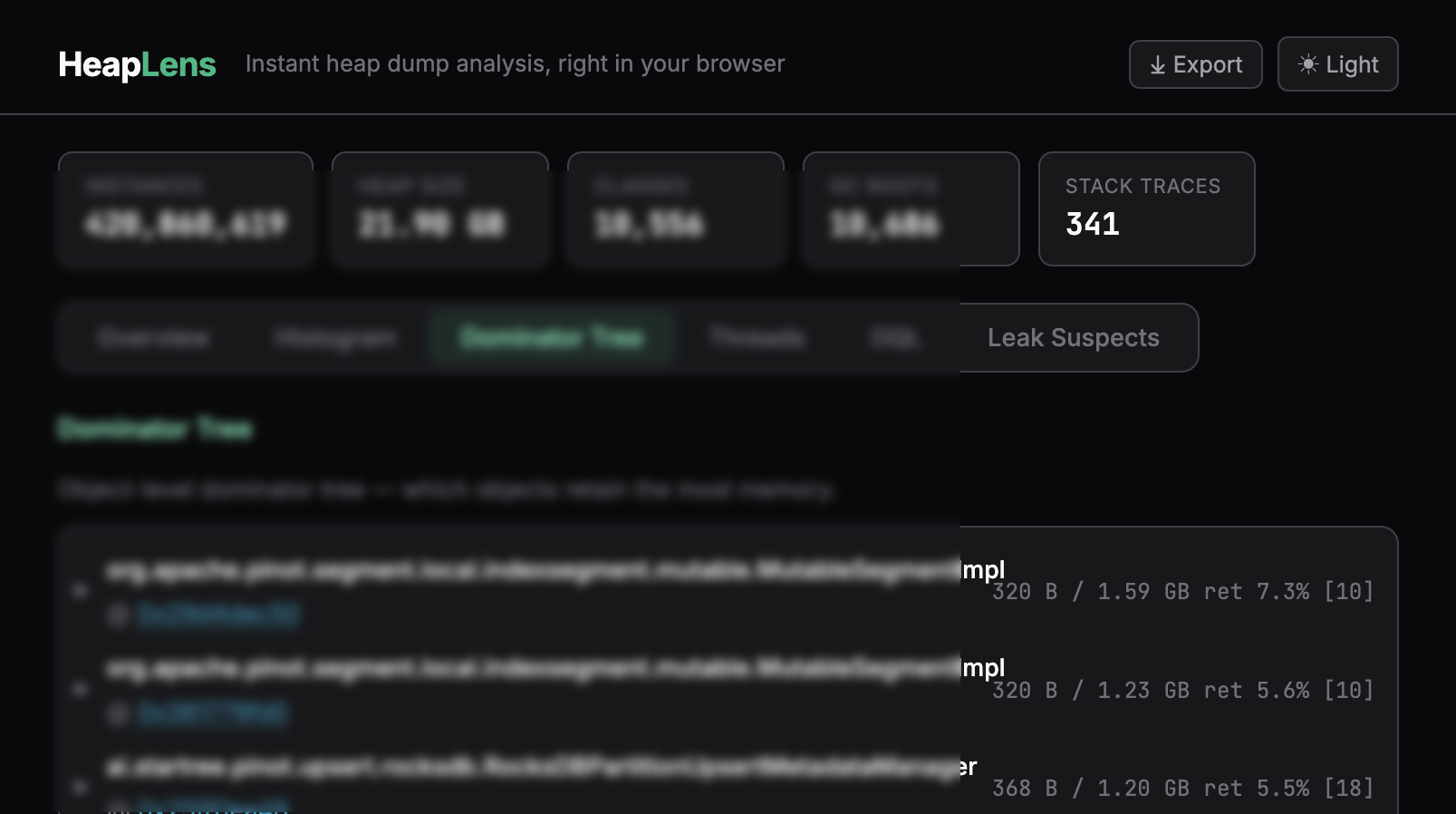
- dominator tree with retained-size analysis & gc root paths
- oql — sql-like queries over heap objects
- mat-style leak suspects with dominator-chain dedup
- thread view with stack traces and retained object correlation
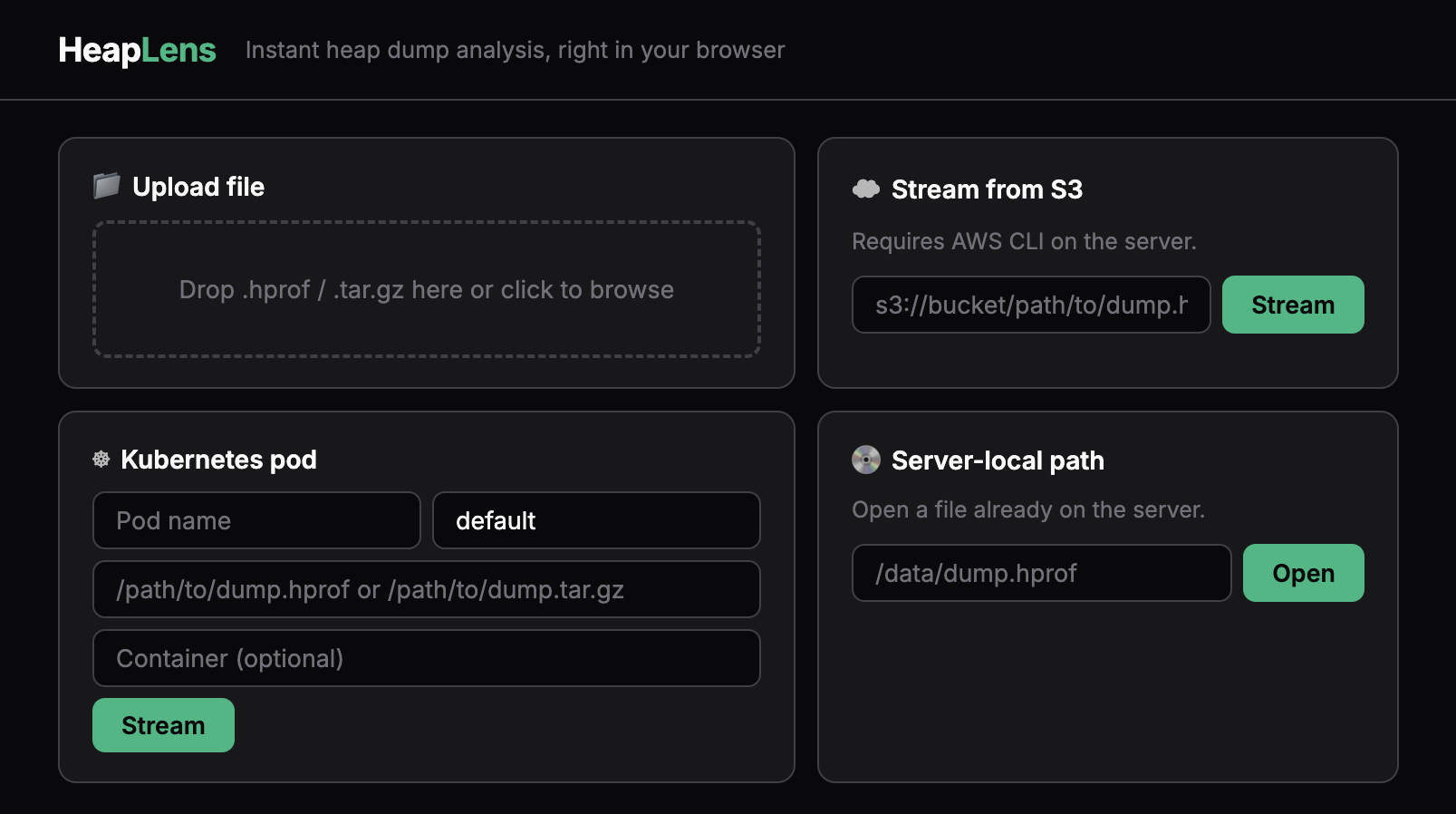
- import from browser, s3, k8s pods, or local path
perf (5 gb / ~72m objects)
- histogram (streaming)< 1s
- reference extraction~60s
- dominator tree~25s
- retained sizes~15s
architecture
- parser — streaming visitor, zero-copy mmap
- graph — csr adjacency, lengauer-tarjan dominators
- import — frontier file reader for concurrent parse